Sharding multi-tenant Postgres databases
PgDog is a proxy for sharding Postgres, without changing your app or your database. Last week, we added support for two new sharding algorithms: values range and list. This is similar to table partitions, except it’s done outside the database and allows you to split your data between multiple servers.
If your app is multi-tenant and you need to physically isolate your users, PgDog can provide a transparent routing layer for your queries. The tenants are set in the config and can be deployed immediately, with zero downtime.
Sharding basics
If this is not your first time here, you can skip straight to configuring tenants. For everyone else, a quick introduction to sharding.
PgDog has two ways for routing queries between shards: automatically using a SQL parser or manually with hints provided by the application. Automatic routing requires the presence of a sharding key: a column in all tables that identifies a tenant. The column can have any name, but for the purposes of this article, let’s call it tenant_id.
For automatic routing to work, the column should be present in all queries. For example, if you’re fetching data from a table, add the column to the WHERE clause:
SELECT * FROM invoices WHERE tenant_id = 1;
Using a built-in SQL parser, PgDog will extract the tenant_id from the query and send it to one of the shards. Inserting new rows works similarly:
INSERT INTO invoices (tenant_id, amount) VALUES ($1, $2)
As long as the sharding key is clearly identified, PgDog will extract its value from the list of parameters and route the query to the matching shard. Both normal and prepared statements are supported out of the box.
COPY
COPY is the quickest way to ingest data in bulk into Postgres and PgDog built special support for cross-shard (i.e., cross-tenant) ingestion. Using a specially written parser, it can extract the sharding key from the input and send each row, in parallel, to whichever shard it belongs, using the same sharding algorithm as regular queries.
The sharding column should be identified in the query and written in the correct order in the input, like so:
COPY invoices (tenant_id, amount) FROM STDIN CSV HEADER;
All COPY formats are supported: text (created with pg_dump), CSV, and binary. If your CSV includes a header, it will be sent to all shards automatically, along with the data.
Manual routing
For manual routing, you can set the shard number inside a transaction, like so:
BEGIN;
SET pgdog.shard TO 1;
-- All queries in this transaction will go to shard 1.
This allows your app to use the same Postgres connection to talk to multiple databases, without maintaining multiple connections manually.
Configuring tenants
For routing to work, PgDog needs to know which shard contains data for any given tenant. For range-based and list-based sharding, this is set in the pgdog.toml configuration file.
If you need to add another tenant, first add the corresponding Postgres server to the list of databases:
[[databases]]
name = "prod"
host = "10.0.0.1"
shard = 0
The shard number should be unique across all databases called “prod” and indicates the position of the database in the cluster. Shard numbers start at 0 and you can have as many shards as you need: PgDog can maintain millions of connections to thousands of databases.
Since we automatically extract the sharding key, we need to know which column to look for in all queries. You can specify the column name and its data type in the config:
[[sharded_tables]]
database = "prod"
column = "tenant_id"
data_type = "bigint"
Unlike hash-based sharding that splits data evenly between all shards, list-based and range-based algorithms require an explicit mapping between values and shard numbers. Adding this mapping is done in the config as well.
List-based sharding
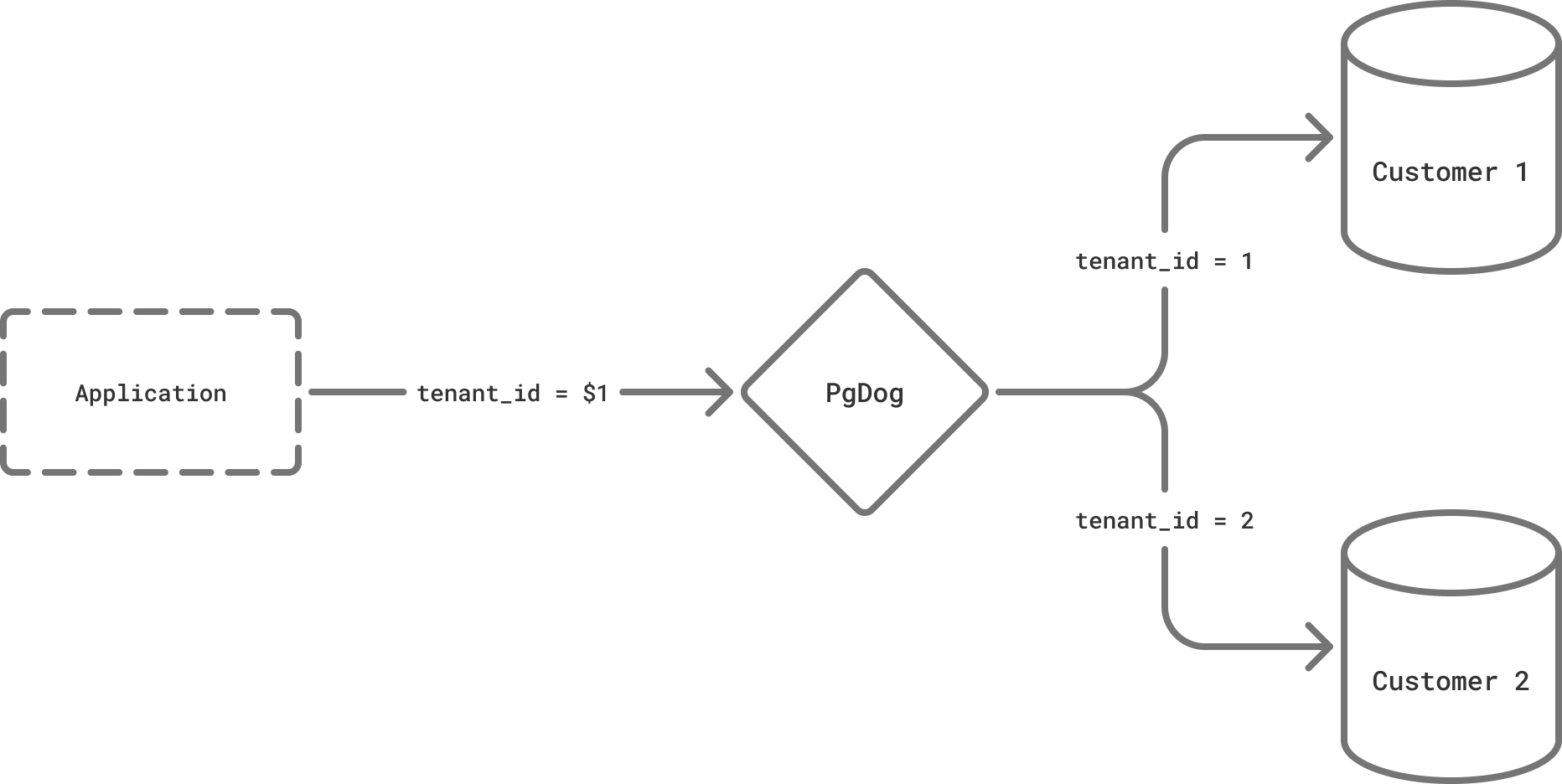
For list-based sharding, for each list, add it to the config, like so:
[[sharded_mappings]]
database = "prod"
column = "tenant_id"
kind = "list"
values = [1, 2, 3] # tenant_id = 1 OR tenant_id = 2 OR tenant_id = 3
shard = 0
PgDog builds an in-memory hash table with the values-to-shard mapping. Calculating a shard number for each sharding key is a quick, O(1) constant time operation, so you can specify as many shards and values as you need.
Since we can calculate the shard number for each tenant efficiently, it’s completely fine to have shards with just one tenant, e.g., values = [4].
Range-based sharding
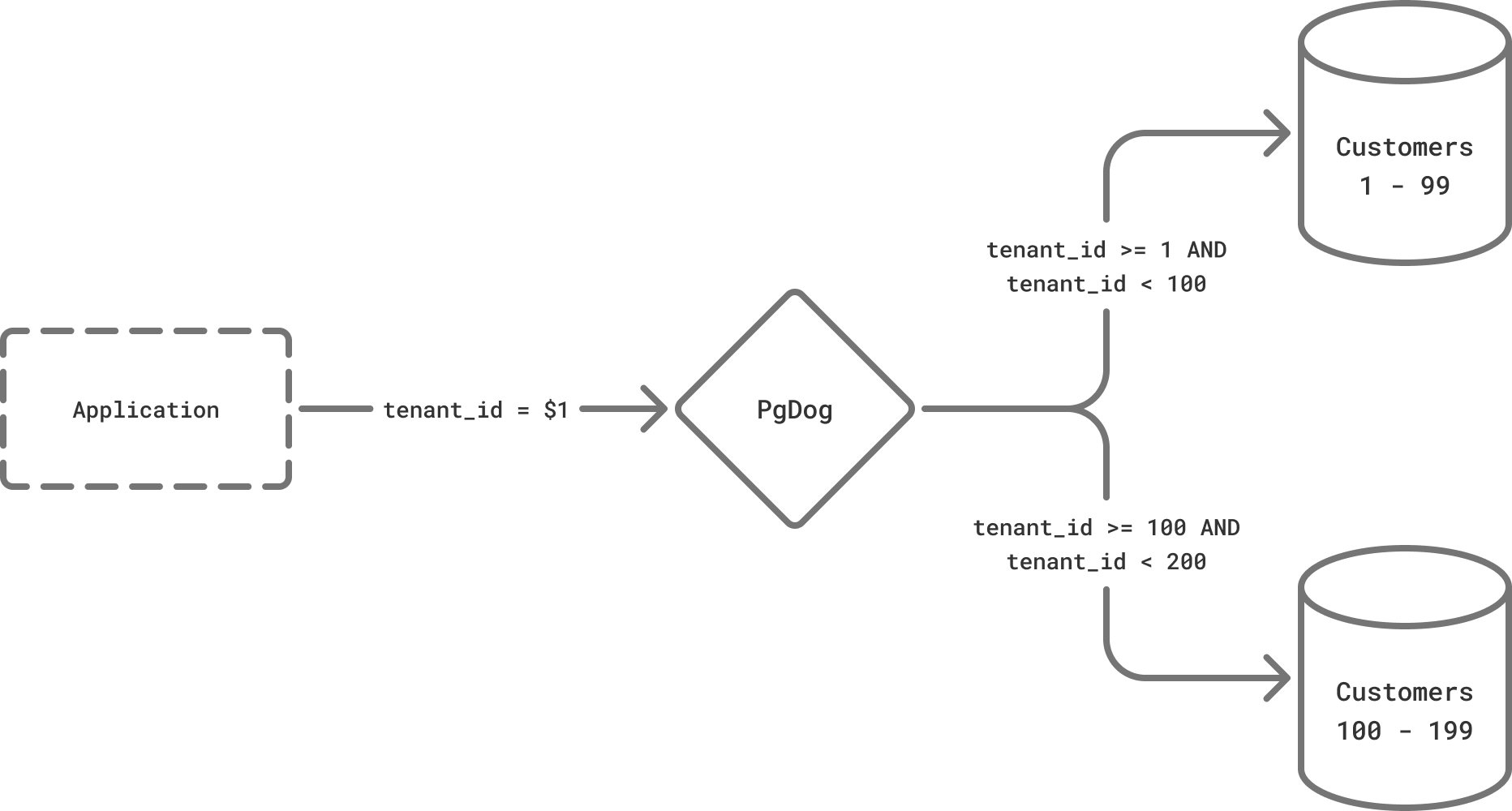
For range-based sharding, you can specify a range of values that should be routed to a shard, like so:
[[sharded_mappings]]
database = "prod"
column = "tenant_id"
kind = "range"
start = 1
end = 100
shard = 0
The range works just like Postgres partitions, with the start value included and the end value excluded. This translates to the following WHERE clause filter: tenant_id >= 1 AND tenant_id < 100.
Supported data types
As of this writing, PgDog supports BIGINT and VARCHAR (or TEXT) based sharding for both list-based and range-based algorithms. More data types like UUID, TIMESTAMP and others will be added soon. If you’re deploying PgDog and a data type you need is not supported, let us know, and we’ll add it quickly.
Cross-tenant queries
PgDog has basic support for cross-shard queries. If your app doesn’t or can’t provide a sharding key, by default, PgDog will send that query to all shards, collect the results in-memory, and send them to the client as if they came from just one database.
This currently also works for sorting and some aggregates, like MIN, MAX, SUM, and COUNT. We’re building a query engine that will handle many complex scenarios, including cross-shard transactions and joins. However, it may not be what you want for multi-tenant applications. For this and other use cases when you want to query only one shard at a time, it’s possible to disable cross-shard queries entirely:
[general]
cross_shard_disabled = true
If they are disabled, PgDog will return an error for any query that doesn’t have a sharding key or isn’t using manual routing.
Roadmap
PgDog is a free and open source project and is built together with the community. Our roadmap is public and feedback is always welcome. Multitenancy has been requested several times and is being developed as a core feature. If you have thoughts on use cases you’d like to see supported, give us a shout on Discord or by email.