Replicating Postgres production traffic
Making changes to Postgres in production is risky. Anything from adding columns to tweaking settings can cause an outage. To make this easier, we built a feature called mirroring.
Mirroring copies queries, byte for byte, from any database to another. PgDog is a proxy, so it does this with just one config change. You can observe what impact changes will have to a database when it’s hit with production traffic.
How mirroring works
PgDog understands the Postgres wire protocol. When a client sends it a query, PgDog forwards it to the server and at the same time, copies the same request to the mirror database. This happens in the background, in a separate asynchronous task, so it doesn’t affect normal query traffic. The query execution results are received and discarded, maintaining a good connection state.
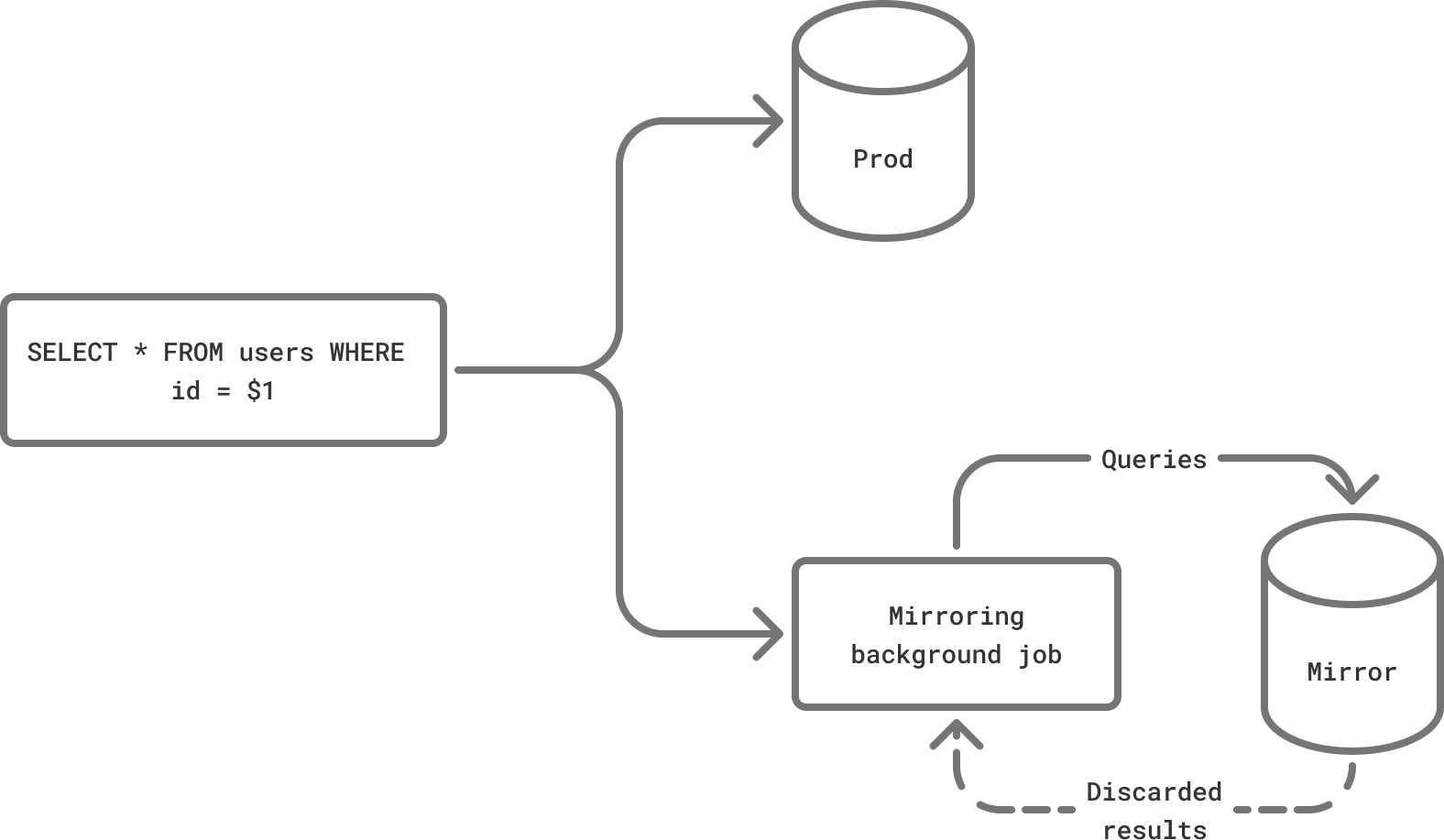
Mirroring architecture
Managing traffic
The mirroring task uses a separate connection pool. It can dynamically scale the amount of queries the mirror receives, without affecting regular traffic. Requests that aren’t immediately sent to the database are placed into a queue until there is capacity to run them.
Mirror queue
Since we don’t know how quickly the mirror will absorb traffic (it’s often the point of mirroring to find that out), the background task has a queue. All queries are placed into the queue first and the mirror picks them out one at a time.
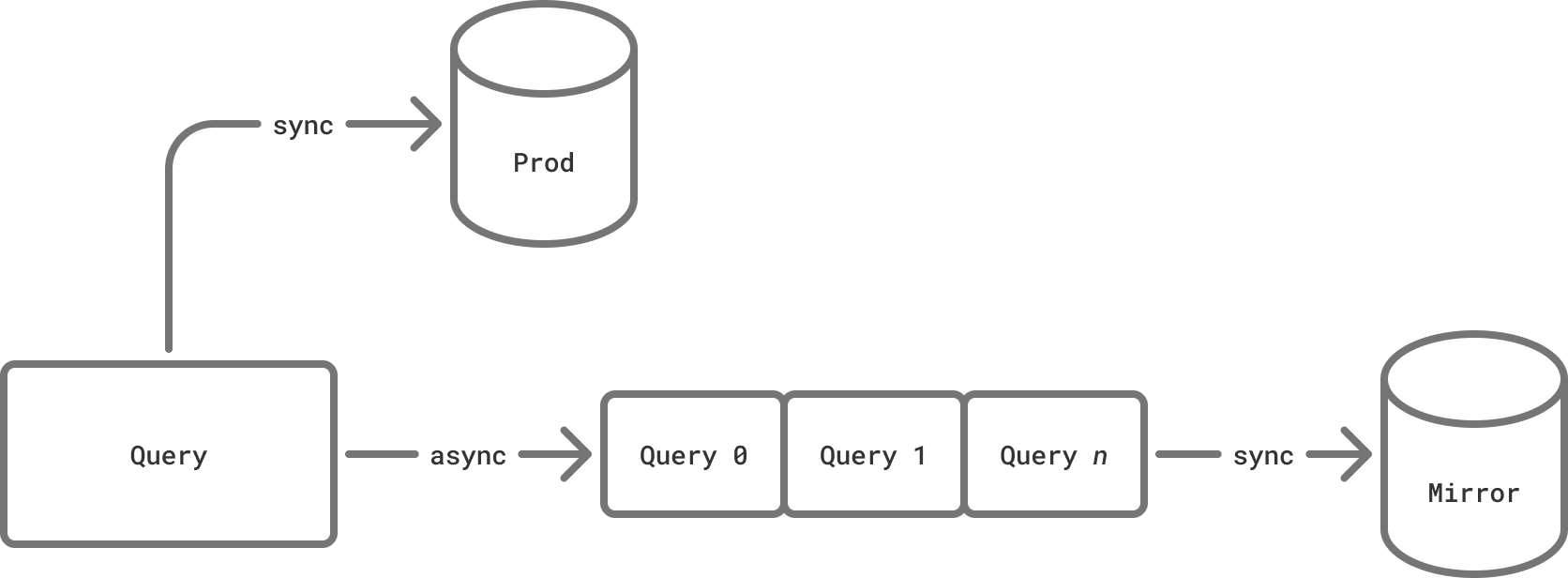
Background queue
If the queue falls behind, queries won’t get lost while it catches up. The queue has a configurable limit: if it’s reached, all subsequent queries are discarded until there is space again. This allows for graceful recovery in case of intermittent failures of the mirror database.
Each client connected to PgDog has its own, separate queue. The scales the amount of replicated traffic directly with production, while leaving slack in the system for errors.
Use cases
Replicating production traffic has many interesting applications. The most obvious is to test the effect production queries will have on another, non-production database. You can change Postgres configuration parameters, like shared_buffers, max_wal_size, checkpoint_timeout, etc., and see what that will do to performance. Some of these require the database to be restarted, so doing this directly on a production database isn’t practical.
Warm up replicas
Mirroring can be used to send real queries to a database that we just created, before making it serve real traffic. This is especially useful on managed services like AWS.
RDS Postgres replicas are created from disk snapshots that are stored in S3. When the database is first launched, its actual disks are pretty much empty. As Postgres accesses its data files, they are dynamically fetched from the snapshot and written to EBS. This is pretty slow, so placing a replica into production without a warmup period can cause an outage.
With PgDog, you can mirror traffic to the replica safely, while it’s warming up its disks with tables and indices that are actually used in production. For databases that mostly store cold data, realistic queries are considerably better than tools like pg_prewarm.
Sharding
Since mirrors are separate databases, they can be different from production. If you’re considering sharding, you can set up a sharded database cluster and replicate traffic to see how well PgDog handles it, without making a single change to your main database.
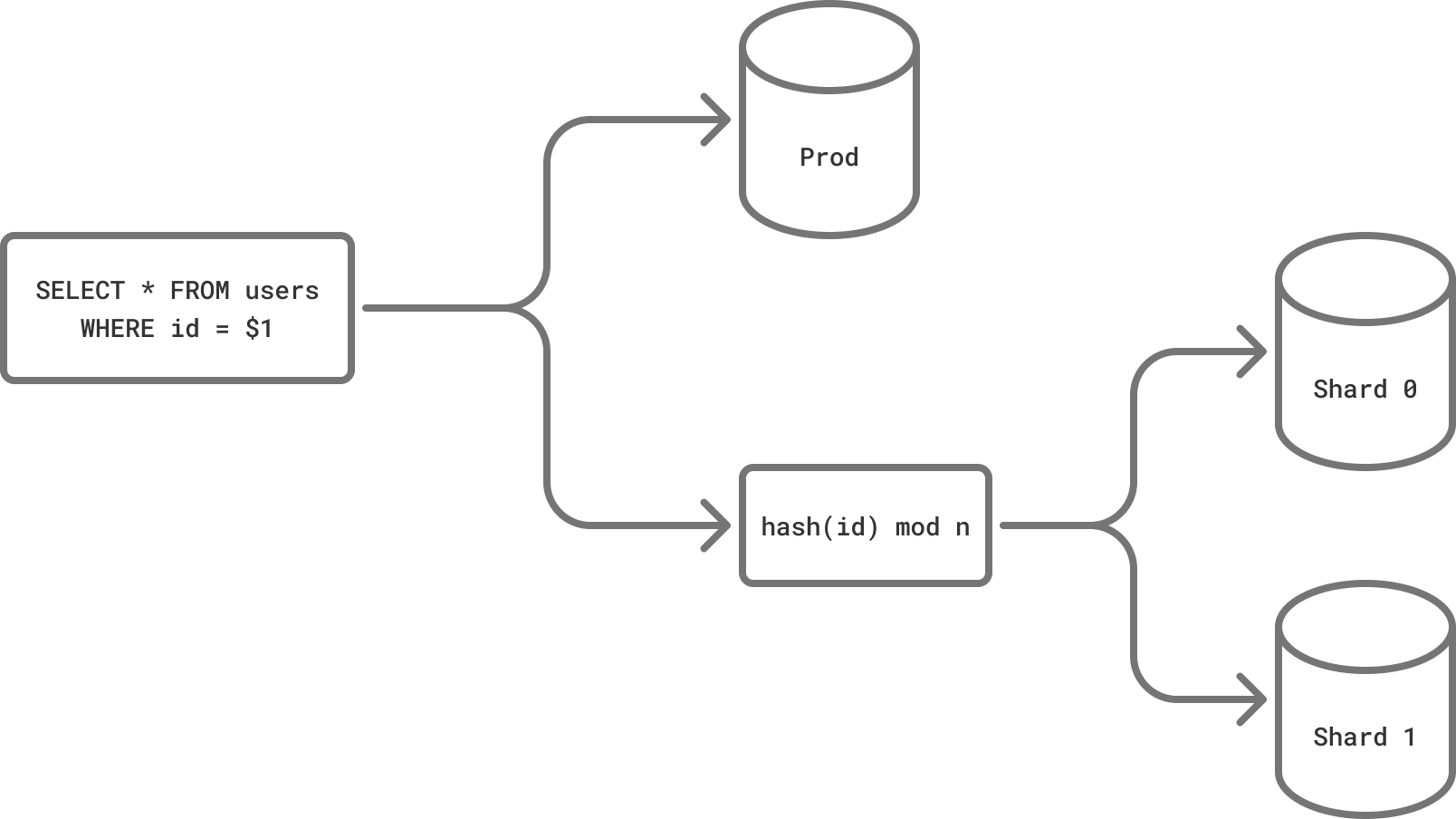
Testing sharding
Protocol internals
PgDog handles Postgres queries in a special way that makes this not only possible, but actually reliable. The Postgres wire protocol is stateful: messages change the server behavior in a way that requires synchronization. If a partial request is sent over, the connection often needs to be closed.
To avoid this, before matching a client to a server, PgDog saves the whole request into an internal memory buffer. If the client is using the simple protocol, that’s just a Query message. The extended protocol (prepared statements) is buffered all the way to Sync (or Flush). The entire buffer is then sent to both the main server and the mirror.
If the async task falls behind, e.g., because the staging database is not performing well under load, the entire request is discarded. Subsequent requests will find the server connections in a good state and can continue executing.
Give our documentation a read to learn how to setup mirroring for your databases.
Demo
Check out this demo video to learn how mirroring works.
About us
PgDog is an open source project for scaling PostgreSQL. If this looks interesting, get in touch. We would love to learn about your Postgres experience. You can also find us on Discord.