Primary keys in sharded databases
A primary key is a column that uniquely identifies each row in a table. Postgres handles this automatically in single-database setups, but sharded databases require additional checks to ensure values are globally unique across all shards.
We’re building schema management into PgDog to solve this problem. This post explains how we ensure column uniqueness directly inside Postgres without extensions or external dependencies.
Problem statement
If you have just one database, this just works:
CREATE TABLE users (
id BIGSERIAL PRIMARY KEY,
name VARCHAR NOT NULL
);
The BIGSERIAL PRIMARY KEY expands into a unique index with a not null constraint and a sequence to generate unique values. New users inserted into the table automatically get a unique identifier:
INSERT INTO users (name)
VALUES ('Wicked Witch of the West')
RETURNING id; -- This returns 1
However, sharded databases create a problem. Each shard has its own sequence that generates its own values. Since shards operate independently without knowledge of other shards, each one generates its own sequence values, causing your application to see identical user IDs for different users.
There are workarounds, but they have significant drawbacks. You could use a different identifier data type like UUID. UUIDs are randomly generated and extremely likely to be globally unique. However, this approach requires:
- Schema changes, which are difficult at scale
- Client-side ID generation, which requires code changes
This approach has serious limitations from both DevOps and application perspectives. UUIDs cannot be sorted chronologically (until UUIDv7 support arrives in Postgres 18), and most ORMs rely on sorting primary keys to produce records in deterministic order.
Another workaround involves external ID generation services. These services track generated identifiers and produce unique numbers on demand. To achieve high availability, they use complex quorum algorithms like Raft or Paxos. This approach is arguably worse than UUIDs because it introduces an external, complex single point of failure to your architecture.
Fortunately, there’s a simpler, faster, and more reliable solution.
Sharded sequences
PgDog uses Postgres PARTITION algorithms for sharding. This design choice allows us to run the same algorithm inside both the proxy and the database, enabling data consistency validation directly inside Postgres with pl/PgSQL functions.
For hash-based partitions, Postgres exposes the satisfies_hash_partition function to validate whether a value belongs in a particular table partition. This function takes the following arguments:
| Argument | Description |
|---|---|
| Table OID | Postgres identifier for the partitioned table. |
| Modulus | Total number of partitions. |
| Remainder | The partition number. |
| Data | The value to be inserted into the partition. |
Since we use the same algorithm to shard data, “partition number” equals “shard number” in our system. We can use this function to verify that a sequence-generated value matches the shard it was generated on by passing the correct arguments to each shard.
Identifying shards
Each shard is an independent Postgres database that doesn’t communicate with other databases in the cluster. This share-nothing architecture makes PgDog and Postgres resilient to failures. Since PgDog is config-driven, we know each shard number and location at runtime. We just need to pass this information to each shard.
We add the following objects to each managed Postgres database:
| Object | Name | Description |
|---|---|---|
| Schema | pgdog |
Schema that contains all of our tables and functions. |
| Table | pgdog.config |
Table with config values, e.g., shard number, total number of shards, etc. |
| Table | pgdog.validator_bigint |
Empty table, partitioned by hash with a BIGINT primary key. |
| Table | pgdog.validator_uuid |
Empty table, partitioned by hash with UUID primary key. |
| Function | pgdog.next_id_seq |
Get next shard-valid value from a sequence. |
| Function | pgdog.next_uuid_auto |
Get next shard-valid UUID value. |
The config table contains the total number of shards in the cluster and each database’s shard number. It stays synchronized with PgDog’s configuration and updates when cluster topology changes. This information is now accessible to all database functions we write.
The two empty tables provide their OIDs to pass to satisfies_hash_partition. Combined with the shard numbers in pgdog.config, we only need a sequence value to generate globally unique primary keys.
The functions are described below.
Brute-forcing a sequence
Postgres sequences are special tables that track a single value. You can read values using the nextval function. This operation is atomic across all connections, ensuring no two queries ever receive the same value.
BIGSERIAL columns use sequences to automatically generate autoincrementing values. However, only a fraction of these values is valid for each shard in a cluster.
Now that we know the total number of shards, our own shard number, and the data type and algorithm used by the sharding function, we can loop nextval until we get a value that makes satisfies_hash_partition return TRUE.
This logic is implemented in the pgdog.next_id_seq pl/PgSQL function. To use it for generating primary keys, set it as the DEFAULT for the primary key column:
ALTER TABLE users
ALTER COLUMN id
SET DEFAULT pgdog.next_id_seq('users_id_seq'::regclass);
That’s it. Unique identifier generation works directly inside Postgres.
Benchmarks are promising. While we consume more sequence values to generate a single identifier, calling nextval is fast, and since everything happens inside the database, there’s no additional latency from external services.
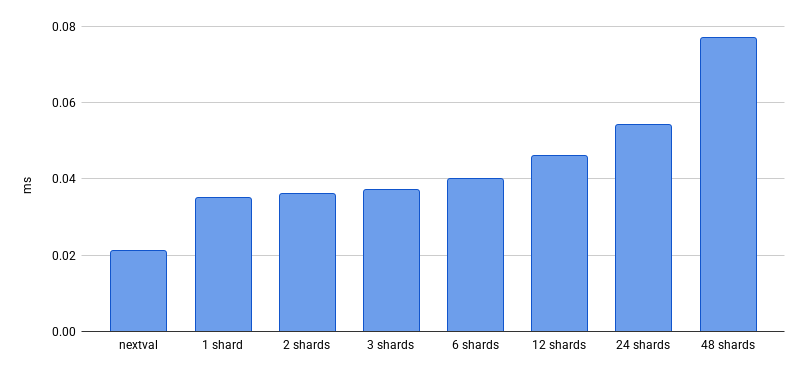
nextval vs. pgdog.next_id_seq
Sequence values live in memory, so fetching one is an atomic +=1 operation. However, the actual sequence value must be written to disk to survive crashes and reboots. Since our brute force search with multiple shards will fetch several values, we can enable an optimization: sequence cache.
Sequence cache fetches a bulk of values from the sequence in advance and distributes them to queries on demand. This happens entirely in memory, without touching disk. If the database server crashes, there will be a gap in the values not written to the database, but duplicates will never occur. By default, sequence cache is disabled, but you can enable it with one query:
ALTER SEQUENCE users_id_seq CACHE 1000;
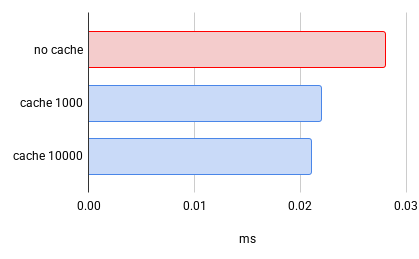
Try it to see the difference. You don’t need sharding to benefit from this optimization. Simply calling nextval in a loop becomes much faster, and if your primary database is under significant load, this will eliminate unnecessary writes to the Write-Ahead Log.
UUIDs
UUIDs are easier to generate in the application, but you don’t necessarily have to. If you’re using gen_random_uuid() as a default for your identifiers, replace it with pgdog.next_uuid_auto(). Instead of using a sequence, it generates UUIDs until one satisfies the shard requirement.
UUID generation is reasonably fast, and this performs well even on systems with many shards.
Closing thoughts
Databases are not greenfield projects, and making any changes, even for sharding, is hard. If we used a different sharding function, this approach wouldn’t be possible. We try to reuse as much of Postgres internals as possible because they are tested and work well at scale.
If you like what we’ve been doing, don’t forget to give a star on GitHub.