Sharding a real Rails app
People on the Internet say Rails apps don’t scale. That’s wrong. You can spin up as many Docker containers as you have CPUs (and money). What you really need is more databases and that’s where we come in.
If you’ve been here before, skip the intro. For everyone else, PgDog is a Postgres proxy that can shard databases. It parses SQL and figures out where queries should go automatically, using query parameters.
To prove that this actually works, I decided to take Mastodon, an app used by millions of people, and shard its database. Of course, it’s using Postgres.
This is the first in a two-part series. On the path to success, we introduce new features that make PgDog the scaling engine your database can’t go without.
Setting things up
First things first, we needed to deploy PgDog between Mastodon and the DB. If you’re a Rails/Postgres expert, feel free to skip to where things get more interesting.
I’m doing this on my local, so I just had to start the pooler and change the port in config/database.yml to 6432:
config/database.yml
development:
primary:
<<: *default
port: 6432 # Port where PgDog is running
pgdog.toml
[[databases]]
name = "mastodon_development"
host = "127.0.0.1"
port = 5432
PgDog is now in the middle between Mastodon and Postgres and can see every single query that’s flying through:
We’re ready to launch the app, but we are not sharding yet. All we’re doing is running a transactional pooler between the app and the DB. We don’t have a sharding key and all queries are just going to one database.
The sharding key
A sharding key is a column in a Postgres table. Specifically, it’s the value of that column for each row in that table. If you know that column (and its values), you can split that table into roughly an even number of rows, and place them in different databases.
When searching for those rows (i.e., SELECT query), you just need to know the value of the sharding key and you can find the database where the rows are stored.
Sharding a relational database with a bunch of tables requires us to understand how the app works. Picking the right sharding key is important: you can’t easily change it afterwards and, if chosen poorly, performance of your database can get worse.
If chosen right though, the data will be evenly split between databases and each shard will handle 1/N of total application traffic, and that will scale your database horizontally.
Finding the right key
This should ideally be done by someone who knows the app well. They will have a good intuition about where the bottleneck is and which table and column will split the database evenly. For everyone else (including me), the schema can help.
In theory, our ideal table has the most foreign key references. This means that a row in the table we pick has a reference to it in a lot of other tables.
For example, the accounts table has a primary key: id BIGINT. A foreign key to accounts in another table is a column that has the same value as accounts.id. For instance, the statuses table (where a lot of your Mastodon posts are stored) has a column called account_id, also a BIGINT, which is a reference to an account that posted that status update.
If we find a table that has many foreign key references to it in other tables, this means the sharding key is also present in those tables. As long as the app can pass it with most queries, PgDog can route them to a shard.
I’m not an expert on Mastodon, but Postgres is. If you look up the schema directly in the database (\d+ in mastodon_development), you’ll see that all foreign keys are explicitly listed. This is a Postgres feature that ensures data integrity and, in this case, will help us find the right sharding key.
In the best case, your schema looks a little bit like this:
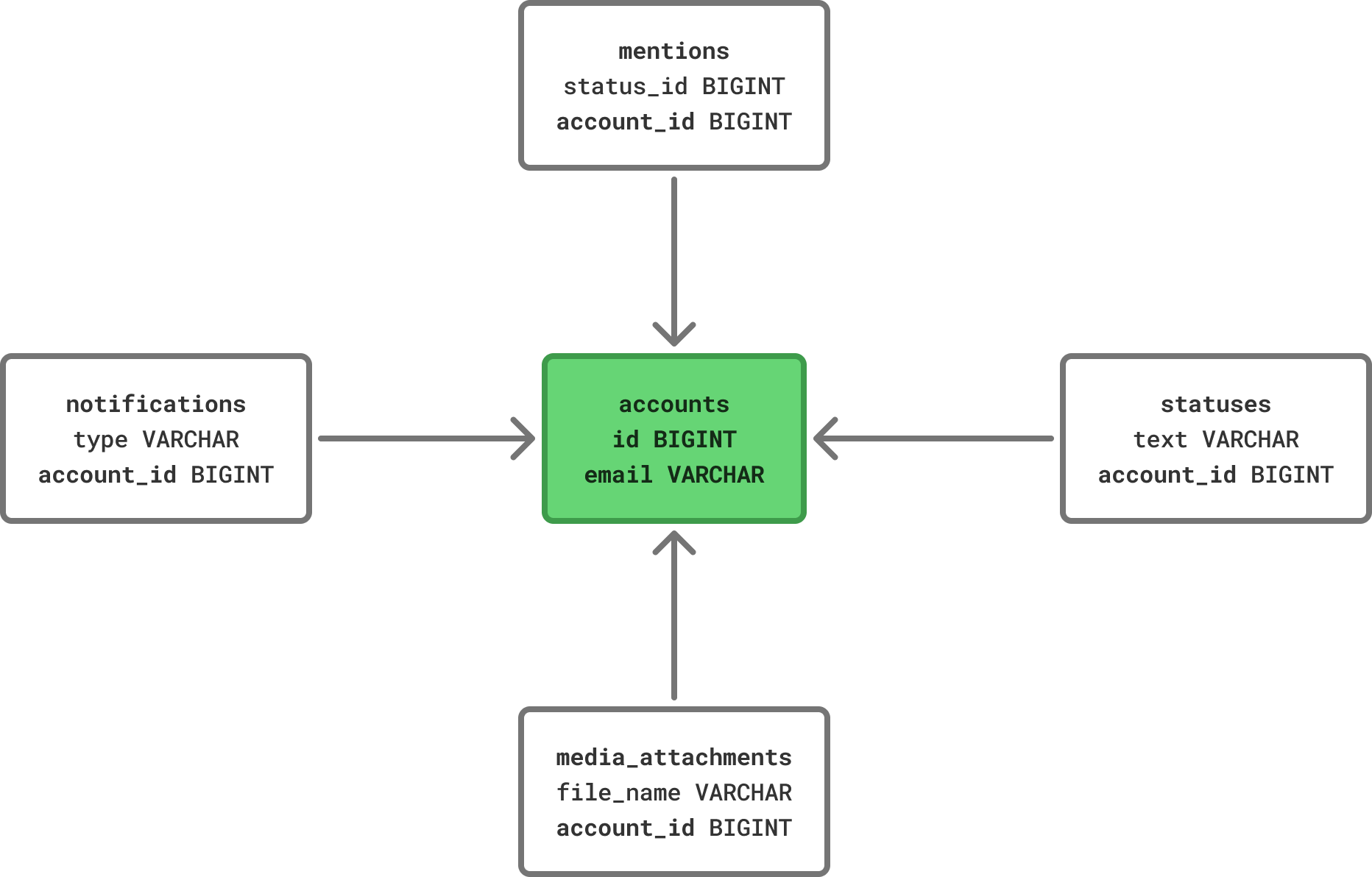
The sharding key is the center of your app’s universe. Most other tables reference it in some way, so if you decide to move parts of it to a different machine, you can pull a bunch of rows from other tables with it.
That’s enough foreshadowing. Using a simple Python script, I found that the accounts table is referenced by 75 other tables, which represents 36% of all tables (205 total) in the DB. While not perfect, that’s a great starting point.
Transitive relationships
Let’s do a quick detour here. 36% seems a bit low; let’s see if we can improve that number.
While accounts are referred to directly from 75 other tables, it’s likely that those 75 tables have, themselves, foreign key references in other tables. Since that relationship is transitive, we can find rows in those tables using a join. When applied recursively, our search function found 123 tables that refer to accounts directly or through another table.

That’s 60% of all tables, which is much better. Our sharding key of choice seems good, but before we can just slap it into production, we need to be sure. And for this, we built dry run mode.
Dry run mode
In a production system, the only real way to know how it works is to observe it, in production. That’s often difficult. I didn’t know if the app passed the account_id in most queries and since I’ve never run a Mastodon server, I had no intuition about it.
To find out, I created a feature called “dry run”. When enabled, every query that goes through PgDog will pass through its internal router. Even if the database isn’t sharded, PgDog will pretend that it is and make a decision about where it should go. If the query has a sharding key, the decision will be a shard number. If not, it will be a cross-shard (or multi-shard) query.
If you’re trying this at home, open up pgdog.toml and add this setting:
[general]
dry_run = true
When enabled, all queries are routed and recorded. The routing decision is ultimately ignored, but we now get to see the queries and the routing decisions PgDog made in the admin database:
admin=# SHOW QUERY_CACHE;
| query | hits | direct | cross |
|---|---|---|---|
SELECT "settings".* FROM "settings" WHERE " settings"."var" = $1 LIMIT $2 |
31 | 0 | 31 |
SELECT "mutes"."target_account_id" FROM "mutes" WHERE "mutes"."account_id" = $1 |
2 | 2 | 0 |
SELECT "lists".* FROM "lists" WHERE "lists"."account_id" = $1 |
1 | 1 | 0 |
For every query that passes through the proxy, we get the query text, how many times we’ve seen it (hits), how many times it was routed to just one shard (direct), and how many times it was sent to multiple shards (cross).
Internally, the router query cache is quite efficient. If the client uses prepared statements (Mastodon, a Rails app, does), they are deduped and only one instance of the statement, with placeholders ($1, $2, etc.), is recorded. Even if your app has thousands of ActiveRecord call sites, the number of queries will be manageable and easily stored in memory.
If your app doesn’t use prepared statements or the extended protocol, PgDog “normalizes” the query using pg_query, removing parameters and replacing them with placeholders. This makes sure the query cache only stores unique queries and keeps the number of entries manageable.
Production metrics
Since we’re now “running in production”, we should be collecting some metrics. At the end of the day, we really just want to know, did we pick the right sharding key? The metrics we’re looking for are exported using a Prometheus endpoint. You can enable it in the config, like so:
[general]
prometheus_port = 9090
To visualize these, I installed a Datadog agent locally, signed up for an account, and created a dashboard. I’ve exported it as JSON, so you can set one up too. Our query router currently exposes 5 metrics:
| Metric | Description |
|---|---|
query_cache_hits |
Number of times a query has been found in the cache and required no parsing. |
query_cache_misses |
Number of times we’ve never seen a query and we had to parse it using pg_query. This number should be low relative to query_cache_hits. |
query_cache_direct |
Number of queries routed to only one shard. We want this to be high. |
query_cache_cross |
Number of queries that had to hit all shards. Ideally, we want this to be low. |
query_cache_size |
Total number of queries in the cache. |
Absolute numbers are fine, but we can summarize them using a percentage. The formula we’ll be using to track how we’re doing is simple:
success_rate = direct / (direct + cross) * 100Once that number reaches 95%, we’re good to go. If all queries have roughly equal performance cost, this indicates 95% of database utilization is spread evenly across shards. If we wanted to be more precise (always a good idea), we can measure how expensive each query is and treat that as the number (summed across all queries). More on that in the next article.
It was time to measure how many queries were handled correctly. I wrote a small bash script to hit my local Mastodon instance with cURL, just to simulate a bunch of traffic, and started recording. The results, at first, were a bit underwhelming:
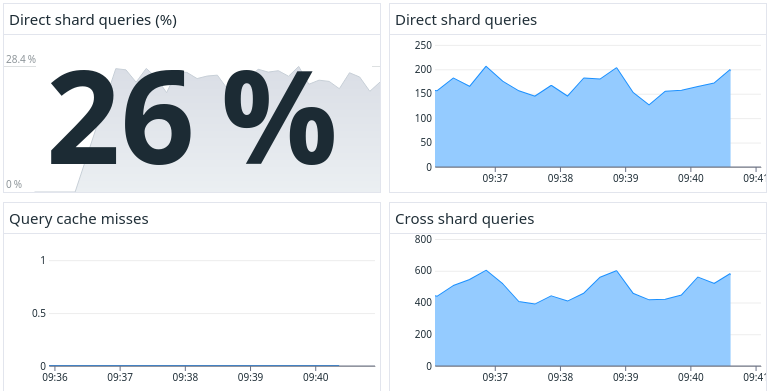
Womp womp. Only 26% of queries that Mastodon sent over to Postgres had a sharding key. It wasn’t zero, but 26% isn’t enough to make this work. If 74% of your queries have to hit all your shards, you haven’t sharded that much, really.
To find out what went wrong, I started browsing the query logs. Some queries had the account_id in them, but most were hitting some tables that aren’t referenced from anywhere. Tables like settings, terms_of_service and site_uploads. Every page load had at least one query referencing those tables (often more) and they had no obvious sharding key. Were we in trouble? Not quite.
Omnishards
Every app has something we call “metadata” tables. They store some info that’s rarely updated but frequently accessed. Back when I was at Instacart, we had tables that stored every single postal code (and their approximate coordinates) in the US and Canada. Those never changed, but we read them on each page load.
Given our sharding key (accounts.id), tables like terms_of_service and others, cannot be sharded. However, if we copied them to all shards, we could join them from any query. If we need to read them directly, we can route that query to any shard, distributing traffic evenly between databases.
To make this work, we wrote another feature, called “omnishards”. Omni, in Latin, means “all”. These tables are present on all shards and have identical data. I quickly looked through the schema and the query cache log, found some tables that looked like they would fit the bill, and added them to pgdog.toml:
[[omnisharded_tables]]
database = "mastodon_development"
tables = [
"settings",
"site_uploads",
"ip_blocks",
"terms_of_services",
]
Judging from their names, I guessed (correctly) that they are accessed all the time. For example, ip_blocks is checked for each HTTP request to Mastodon, to make sure the client isn’t a known spammer.
Every time PgDog sees a query that only refers to an omnisharded table, it sends it to one of the shards, using the round robin load balancing algorithm. This makes sure the load is evenly distributed between shards.
After reloading the config and restarting my cURL script, the numbers looked much better:
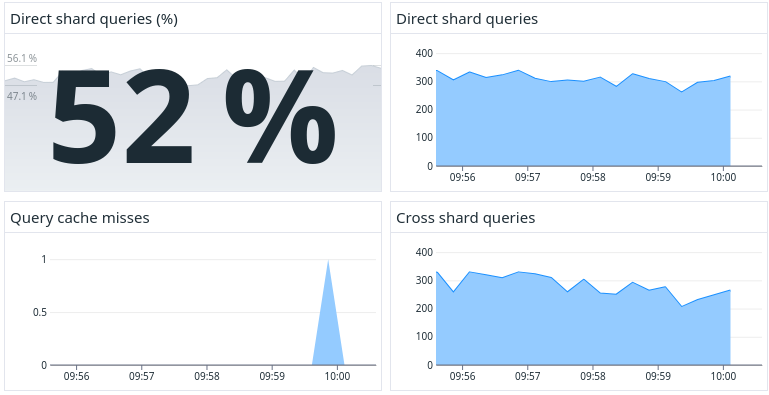
Without changing a single line of code, 52% of DB queries were sharded. While not the magic number (95%) we are looking for, it’s an amazing start. Cherry on the top: our query cache hit rate was 99.99%. We ended up almost never using pg_query to parse SQL, so there was virtually no performance overhead for this feature.
Handling writes
Cross-shard queries in a read-only context aren’t the end of the world. Eventually, we’ll find and fix them. Until then, they will hit all shards, but the client will receive the right data; PgDog makes sure of that. However, if we send a write query and it gets routed to the wrong place, things could get messy.
It was time to test the real thing: creating posts.
Using the web UI this time, I went to the home page, submitted a post (a picture of my dog, of course) and looked at the query log. This is what it looked like on the backend:
BEGIN;
INSERT INTO "conversations" (
"uri", "created_at", "updated_at"
) VALUES ($1, $2, $3) RETURNING "id";
INSERT INTO "statuses" (
"account_id", "conversation_id", [...]
) VALUES ($1, $2, [...]) RETURNING "id";
COMMIT;
It happens inside a transaction (good!), but the first query gave me pause. It’s inserting data into the conversations table which does have a transitive relationship to accounts through statuses. However, the query itself has no sharding key. The second query did, but PgDog would see it too late. It needed to make a routing decision for the first query before executing the second.
From a first glance, there was no way to handle this gracefully. We couldn’t just pause the first query until we received the second: ActiveRecord expects a response to a query before sending the next one. Then I remembered: we built manual routing for this exact use case.
The client knows where the query should go, so it can easily provide it as context to our query router. All we needed was a way to pass that context through.
Manual routing
Up until this point, I thought we could do manual routing using comments. It looks a bit like this:
/* pgdog_sharding_key: 1234 */ INSERT INTO my_table VALUES ($1);
In theory, that works, but in practice it’s pretty hard to add a comment to a query from an application. Even ActiveRecord, which has the #annotate method, doesn’t always work. It can add comments to SELECT queries, but all others can’t be annotated (not quite sure why, honestly).
Thankfully, we are in control of the Postgres protocol so we can do pretty much anything, as long as both the client and server (PgDog) are on the same page.
To pass the sharding key in this transaction, we decided to use the SET command. It’s valid SQL and it adds a temporary session variable with the sharding key value:
BEGIN;
SET "pgdog.sharding_key" TO '114384243310209232';
-- Regular queries.
COMMIT;
All the client has to do is send that query first, inside a transaction, and PgDog would know which shard to use.
Using Rails logs, I found the code that creates the post and wrapped it with the sharding context. That worked, but the code looked kind of ugly and was easy to misuse: if it’s executed outside a transaction, it wouldn’t work.
To make this easier, I wrote a Ruby gem. Ruby, secretly, is one of my favorite languages. Things like these are really easy to implement and they just work. The gem is called pgdog and it’s available on rubygems.org. It’s a bit light on the documentation at the moment (I’m still a solo act), but here’s how it works:
PgDog.with_sharding_key(@account.id) do
# Read/write directly from/to the matching shard
end
Instead of using ApplicationRecord#transaction, use PgDog#with_sharding_key and the following will happen:
- A transaction will be started automatically
- The gem will send the
SETstatement before all other queries
The diff ended up being pretty short and easy to review:
- ApplicationRecord.transaction do
+ PgDog.with_sharding_key(@account.id) do
@status.save!
end
With this issue handled, both read and write queries were routed, correctly, to one shard. We were running in dry run mode, haven’t broken production, and our goal (95% of queries hitting just one shard) was getting closer.
Closing thoughts
That’s all I had time for this week. While I love to code, to get this off the ground I have to do a lot of other stuff. If you’re an engineer, you probably don’t want to know what’s really involved in running a startup.
There are a few (partially) unanswered questions, in no particular order:
- How do we generate primary keys? Spoiler alert: we have a workaround, directly in Postgres, that we’ll cover in a subsequent post.
- How many code changes do we need to make sure the sharding key is available most places? I suspect, in a well maintained code base, that number will be quite low (due to code reuse). For messy apps, see next point.
- Can we automate some code changes? I’m guessing in the age of AI, the answer is probably. As long as a human checks the work, of course. We just need to “join” the Rails logs with the queries in PgDog’s query cache.
- How can we maintain data integrity across omnisharded tables? At Instacart, we used logical replication (and
COPY). PgDog supports cross-shard transactions, but we’ll need to use two-phase commit before using them in production. - How can we protect shards from accidental cross-shard writes? We have a trigger that validates INSERTs (and UPDATEs). More on this in the next post.
Next steps
If this is interesting, you should get in touch. PgDog is looking for early adopters! For everyone else, we’re getting closer to a production release and should have v1.0 released in June (2025, if you’re reading this from the future). A GitHub star is always appreciated.