Sharding Postgres at 6.5 GB/s
Jul 24th, 2025
Lev Kokotov
For quite some time now, moving large amounts of data in and out of Postgres has been a challenge. This changed in Postgres 16: we can now create logical replication slots on binary replicas. This simple change allows PgDog to parallelize data synchronization across multiple databases, migrating data into a sharded Postgres database as fast as the network will allow.
On EC2 (and therefore RDS), this can be as fast as 50 Gbit per second. In this article, we describe how PgDog hooks into the logical replication protocol to shard (and reshard) Postgres databases, online, without affecting production operations.
Background
The key to sharding Postgres without downtime is logical replication. It allows moving data in real time between two databases. Any other approaches, like manual copying or dual-writing at the application is likely to lose data. Therefore, to make sharding work, we need to inject ourselves into the replication stream and split it between multiple databases.
The problem
Postgres replication works on the basis of replication slots. They are markers in the write-ahead log that prevent Postgres from deleting it until the data made it to wherever it needs to go, either a replica or any other application that speaks the Postgres replication protocol. A bit of foreshadowing: as of #279, PgDog is that application.

Up until Postgres 16, replication slots could only be created on the primary. This forced all in-house sharding solutions to read data from one database, adding additional load to an already busy system. Even more problematically, it was difficult to parallelize data streams: everything was coming out of the same machine and fighting for the same resources.
At Instacart, we tried logical replication subscriptions as our first sharding strategy and quickly realized that streaming 16 TB worth of tables would take 2 weeks. That was our biggest database at the time. A replication slot would have to be kept open the entire time and, with 300 MB of WAL written per second, more than 350 TB of WAL would accumulate on the primary. With EBS volumes maxed out at 64 TiB, it simply wasn’t possible.
We ended up hacking the RDS backup system and deleting data off of shards instead, but that solution was very manual and error-prone. I accidentally dropped a replication slot half way through, more than once, and we had to start from scratch.
So, if hacking EBS snapshots doesn’t sound appealing, the real problem remains: how can we copy terabytes of data before we run out of disk space on the database?
Parallelize everything
If you’re sharding, the destination for your data is going to be multiple independent databases. If you have, for example, 16 of them, whatever table you’re copying is split into 16 equal parts and written to 16 separate disks, passing through 16 separate shared_buffers and taking 16 independent WALWrite locks.
That’s 16 times faster than one database can do. If a single Postgres database can write at 500MB/second, 16 of them can write at 8 GB/second.
This is a good time to mention that these are real numbers. I’ve been benchmarking PgDog on RDS for the better part of the week and getting consistent results. Similar story for self-hosted instances on EC2 with NVMes, except with lower latency.
If you’re reading our blog, you probably agree that sharding is the solution for scaling writes. This information, so far, wouldn’t be that particularly new or surprising.
What has changed however, is Postgres 16 now supports logically replicating from binary (also called streaming) replicas. These are the kind you can create with a push of a button in any managed Postgres cloud. That opens the door to parallelization in logical replication streams. We can create 16 or more replicas, and use them to copy data in parallel into our sharded cluster.
For each replica, PgDog picks a table, starts a transaction, gets the current LSN, and copies the data over the network, while sharding rows in flight and, in parallel, writing them to the 16 shards in the new cluster.
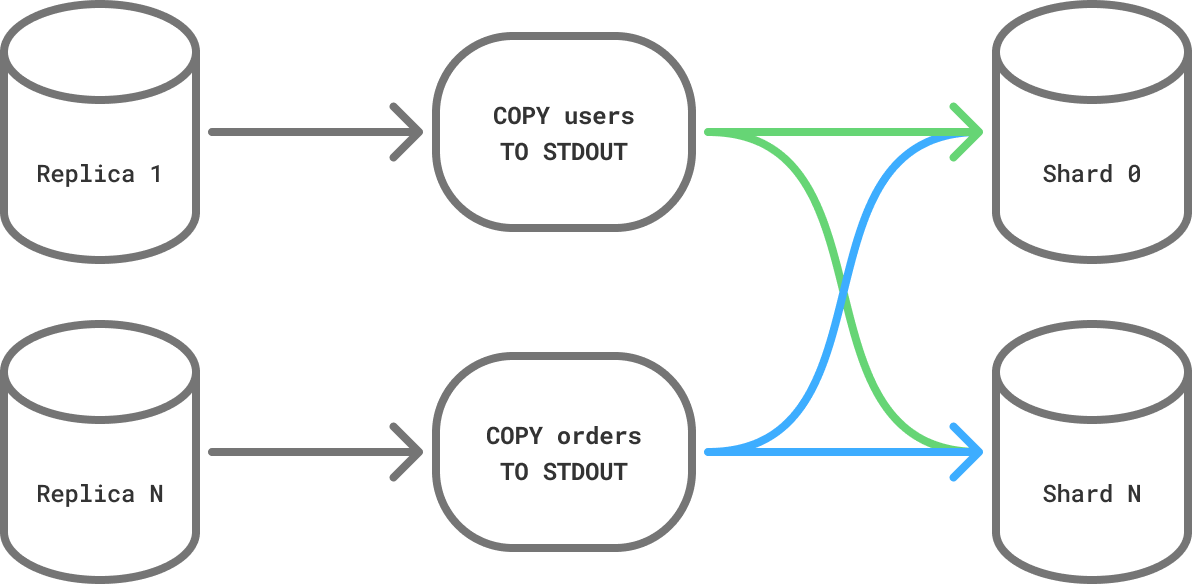
Why do we need replication slots? It allows us to get (and lock) the exact position in the WAL for the table we’re sharding. Think of it as version control, but for data: instead of using a Git hash, Postgres uses a 64-bit number. Without replication slots, we would be guessing as to what rows we actually copied and wouldn’t be able to synchronize with real time table updates.
Once the copy is finished, we can replay whatever rows changed (and keep changing in real time) from the replication slot on the same replica. PgDog keeps track of each table and its LSN, so we can ignore any rows we already received from the initial copy.
Since each replica can easily read at 500MB/second, we can copy, shard, and write data at 8 GB/second. Too bad our network only allows 6.25 (that’s 50 GBit divided by 8). For the first time in history, Postgres is limited by just the network, and that’s a pretty great place to be.
If you have a 16 TB database, PgDog can shard it in 55 minutes. That’s a long lunch and a coffee break.
Using replicas has another advantage: whatever resources we need to move data are not taken away from production. The primary, and other read replicas, if you have them, aren’t affected by this so we can shard data completely online and your application and users won’t notice anything.
There is only one piece left: how do we stream logical replication changes in real time to multiple shards from multiple replicas? To make this work, we flipped the Postgres replication protocol on its head.
Hacking the protocol
When you execute CREATE SUBSCRIPTION on a Postgres database, it creates a connection to the primary, as indicated by the CONNECTION parameter, and starts streaming segments of the write-ahead log.
The stream is composed of messages. Some indicate the state of the WAL, others keep the connection alive by sending periodic status checks, but the most important ones are Insert, Update, and Delete. They contain the row that was either inserted, updated or deleted along with the unique ID of its table.
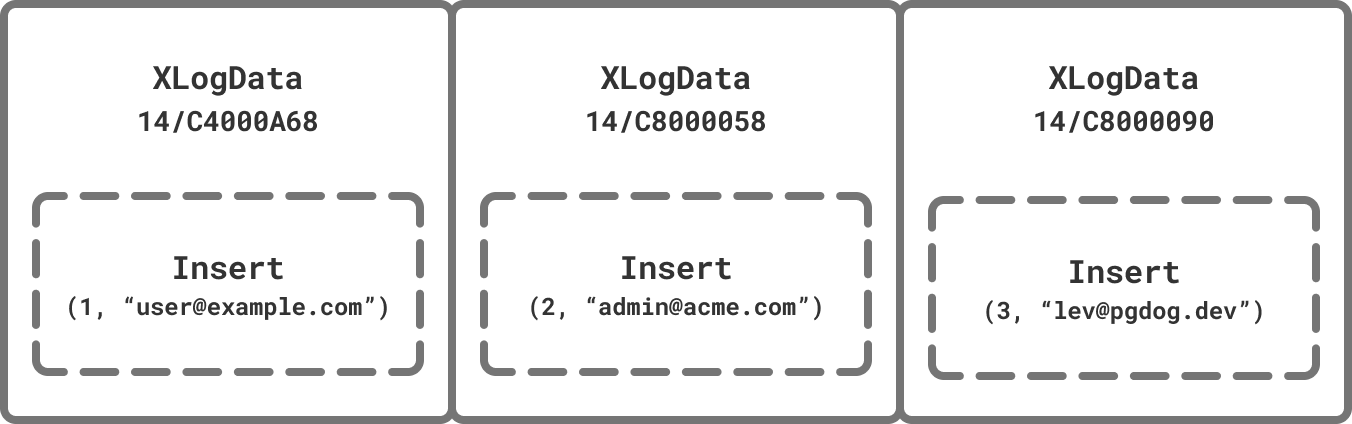
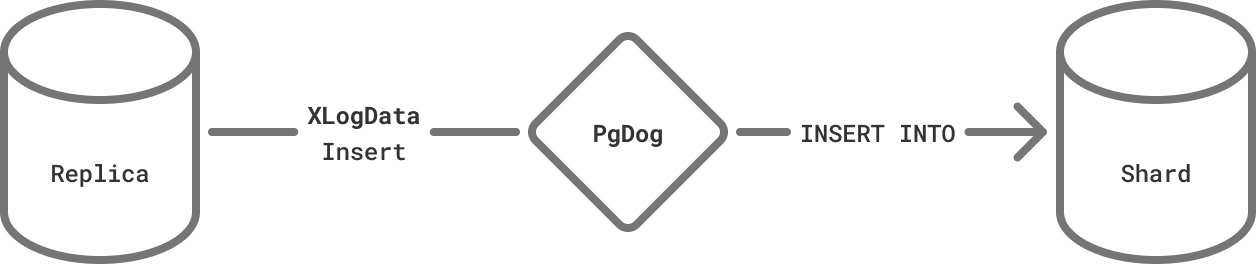
Since the receiver database created the connection, it knows what to do with these messages. However, in our architecture, PgDog is that receiver. It connects to both databases. Postgres connections are created with a specific purpose and can’t process arbitrary messages. Since the shards don’t know they are replicating data, we can’t just forward the WAL messages to them as-is.
To make this work, we rewrote the WAL stream to use the standard Postgres extended query protocol. We know the table name, its columns and their data types, so we can transform any one of the replication messages into a query. For example an Insert message for the "users" table can be rewritten as:
INSERT INTO users (id, email) VALUES ($1, $2)
The statements have the same effect and we can now control how we replay the write-ahead log, which will come in handy later. While this works, replication is considerably faster than just running SQL queries. They have to be parsed, planned and executed. Meanwhile, replication messages are specific instructions to perform a change on some table.
To make this scalable, we took advantage of prepared statements. Instead of sending the query for every Insert message, we prepare the query just once. Then, for each message we process, we only send Bind and Execute messages with the parameters specific to each row.
Next steps
The goal for PgDog is to be push-button scaling product for Postgres. To achieve this, we are building everything from sharding to schema management and distributed transactions.
If you’re looking at scaling Postgres, get in touch. PgDog is an open source project. With an advanced routing layer, connection pooling and now resharding of existing databases, it can scale Postgres to be the heart of your data platform for years to come.
Benchmark details
RDS databases were running on db.m7i.xlarge instances with 4 vCPUs and 16 GB RAM. Each instance was provisioned with 12,000 IOPS and 500MBps EBS throughput, using the gp3 storage tier. The COPY operations were largerly I/O bound to EBS. For each additional replica added, overall throughput increased by ~500 MB/second.
PgDog was running on a single c7i.8xlarge instance with 32 vCPUs. It was CPU & network bound only.