Sharding Postgres at network speed
Up until now, PgDog has been a very smart connection pooler for Postgres. While it could shard and load balance queries, databases are rarely greenfield projects. We needed a way to migrate existing apps to a sharded database and keep all their data, without taking the apps offline.
PR #279 introduced a long promised architectural change: we can now use logical replication to re-shard databases. This happens online and doesn’t affect production performance.
In this post, we describe how the new feature works. In our tests, we were able to copy and shard terabytes of data in a matter of minutes.
A bit of background
If you’re familiar with Postgres logical replication and replication slots in Postgres v16, you can skip straight to architecture. For everyone else, a quick introduction to what’s going on.
Logical replication is key to sharding Postgres online. It allows copying data between two or more databases, in real time. Short of taking your app offline, it’s the only reliable way to do this. Manually running COPY commands or dual-writing in the application code is, more likely than not, to lose data.
Since databases that need sharding are typically large, we needed a way to manipulate logical replication to move large amounts of data in a short period of time. In the past, this has been pretty much impossible. Logical replication was only supported on one database: the primary. It was resource-constrained and would take days to do its job; if anything broke half-way through, we’d have to start from scratch.
When I was first sharding Postgres at Instacart, we were running on Postgres v10. Replicating 16 TB worth of tables, which was our biggest database at the time, would have taken 2 weeks. To keep things consistent, a replication slot was kept open the entire time and, with 200 MB of WAL (write-ahead log) written to the primary per second, more than 230 TB of it would accumulate in the time we needed to copy and shard all the tables. With EBS volumes maxed out at 64 TiB, we would have ran out of disk space and crashed the database.
Things changed in Postgres v16. We can now create logical replication slots on streaming replicas. Since Postgres databases can have many of those, it opened the door to parallelization. If you’re not confused already, you’re about to be, so let’s do a quick detour to explain Postgres replication.
Replicas, replicas everywhere
Postgres has two kinds of databases: the primary and replicas. The primary handle writes: think INSERT, UPDATE, DELETE and other queries that change something. Replicas handle SELECT queries. We call them read queries: they just read data and don’t change anything.
Regular or “not sharded” database clusters can only have one primary. They can have multiple replicas, however. Each replica streams the WAL from the primary in real time. Since Postgres v10, there are two ways to do this:
- Binary (also called streaming) replication
- Logical replication
Binary replication sends over the write-ahead log, as-is. If you use Wireshark or pg_receivewal to take a look inside, you’ll see a bunch of changes to database files, but not much else. For our purposes, it’s not very useful or easy to work with.
Logical replication, on the other hand, is a series of, basically, human-readable commands that tell the receiver, be that a Postgres database or an application like PgDog, what rows have been inserted, updated or deleted along with other useful information like table schemas and transaction state.
Since a primary can have multiple replicas, Postgres needs a way to keep track of which replica has received which portions of the write-ahead log. Without doing so, data loss would occur and replicas wouldn’t be very useful. To do this, Postgres authors created the concept of replication slots.
 Replication slot is a bookmark in the write-ahead log.
Replication slot is a bookmark in the write-ahead log.
Replication slots are markers in the write-ahead log that prevent Postgres from deleting table changes until they made it to wherever they needed to go. Each change, or WAL record as we call them, has a monotonically increasing number, called the LSN (logical sequence number). It uniquely identifies a transaction and allows the receiver to order changes in the same way they happened on the primary.
Since Postgres v16, we can create logical replication slots on any streaming replica. This unlocked the ability to copy tables in parallel. With more machines comes more throughput and that changed the game.
Architecture 2.0
PgDog is no longer just a proxy for applications talking to Postgres. It’s now a stateful application that can create and manipulate replication streams. The new architecture looks a bit different:
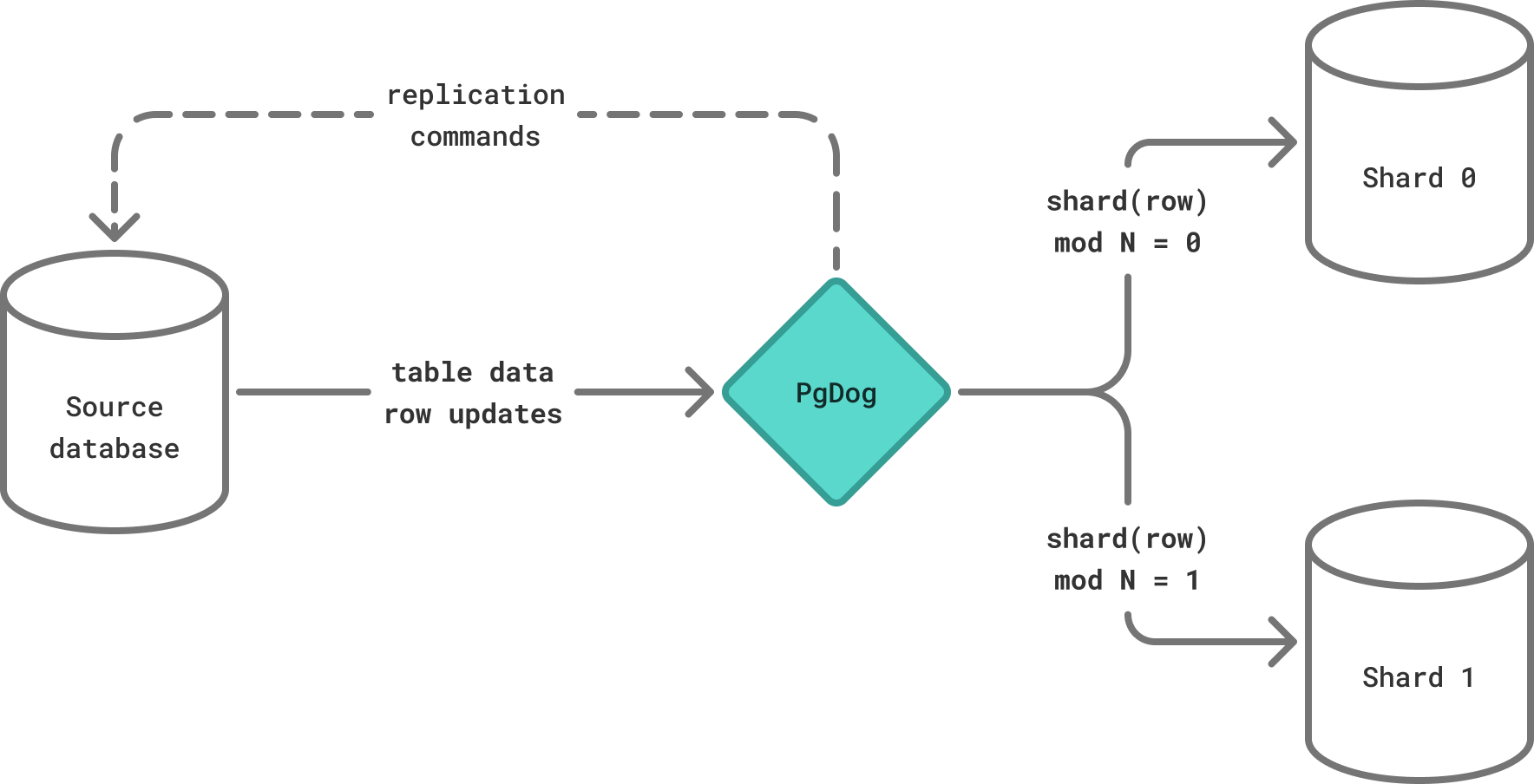 PgDog Architecture 2.0
PgDog Architecture 2.0
Parallelize everything
When re-sharding tables, the destination for table data are multiple, independent, databases. If you configure 16 shards, for example, all tables are split into 16 equal parts. Each part is written to a separate disk, passing through its own shared_buffers and taking only 1 of 16 independent WALWrite locks.
This allows for 16 times more throughput. A single Postgres database, on AWS RDS, can copy a table at 500 MB/second. 16 of them can do the same at 8 GB/second. These are real numbers. I’ve been benchmarking that PR for the better part of the week and getting consistent results.
Since we can use streaming replicas to copy data out, and we can have many of those, we can parallelize both the read and the write part of copying tables. Using 16 replicas (to match our number of shards), we can copy one table per replica and 16x our sharding throughput.
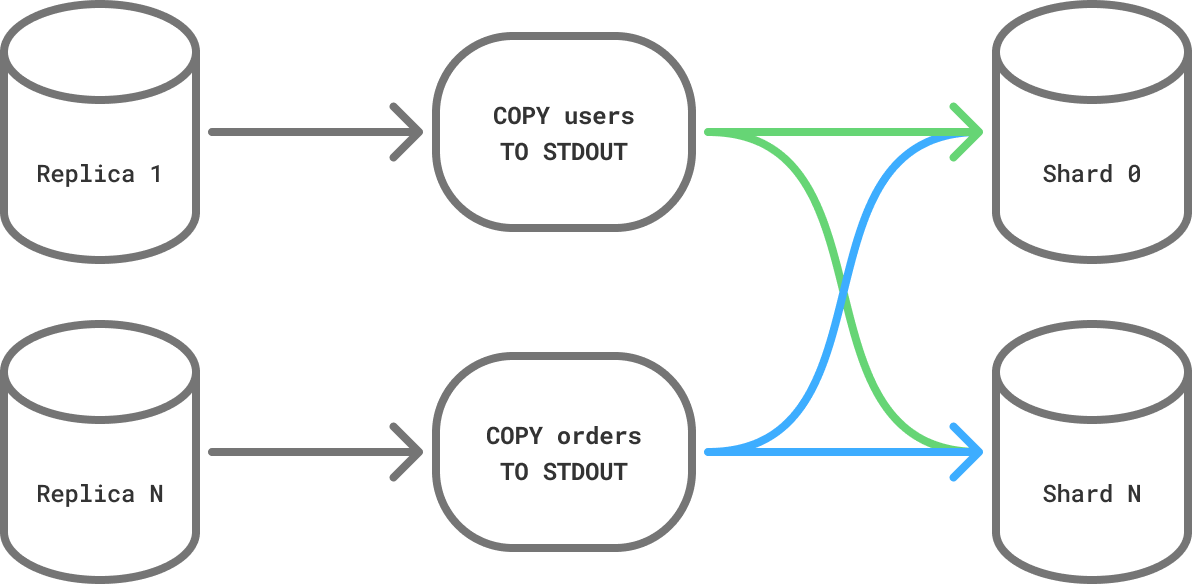 Copying tables in parallel increases throughput by the number of replicas.
Copying tables in parallel increases throughput by the number of replicas.
For each table in your schema, PgDog performs the following steps:
- Pick a replica from the config
- Start a transaction
- Get the current LSN by creating a replication slot
- Copy the table out, splitting rows between shards equally
Why do we need replication slots? They allow us to get (and lock) the exact position in the write-ahead log for the table we’re copying. Think of it as version control, but for Postgres tables: instead of using a Git hash, Postgres uses a 64-bit number. Without replication slots, we would be guessing as to what rows we actually got and we wouldn’t be able to synchronize with real time table updates.
Once the copy is finished, we stream whatever rows changed since the copy started (and keep changing in real time) from the replication slot on that same replica. PgDog keeps track of each table and its LSN, so we can ignore any rows we already received.
Since each stream can read at 500 MB/second and our shards can write at the same speed, we can copy, shard, and write data, at a whopping 8 GB/second.
This is enough to make this process network-bound, even with 10 Gbit NICs. That’s a step function change. If you have a 16 TB database, like we did at Instacart, PgDog could re-shard it in about 55 minutes. That’s a long lunch and a coffee break.
Using replicas has another exciting benefit: whatever resources we need for this are not taken away from production. The primary, and other read replicas, if you have them, are completely isolated, so we can shard data online without your application slowing down.
There is only one piece remaining: how do we stream logical replication changes in real time to multiple shards from multiple replicas? To make this work, we flipped the Postgres replication protocol on its head.
Hacking logical replication
When you run the CREATE SUBSCRIPTION command, Postgres creates a connection to the source database, as indicated by the CONNECTION parameter, and starts streaming segments of the write-ahead log.
If you’re not familiar, this is how you set up logical replication between two Postgres databases.
That stream is composed of messages. Some indicate the state of the WAL, others keep the connection alive by sending periodic status checks, but the most important ones are Insert, Update, and Delete. They contain the row that was either inserted, updated or deleted along with the unique ID of its table.
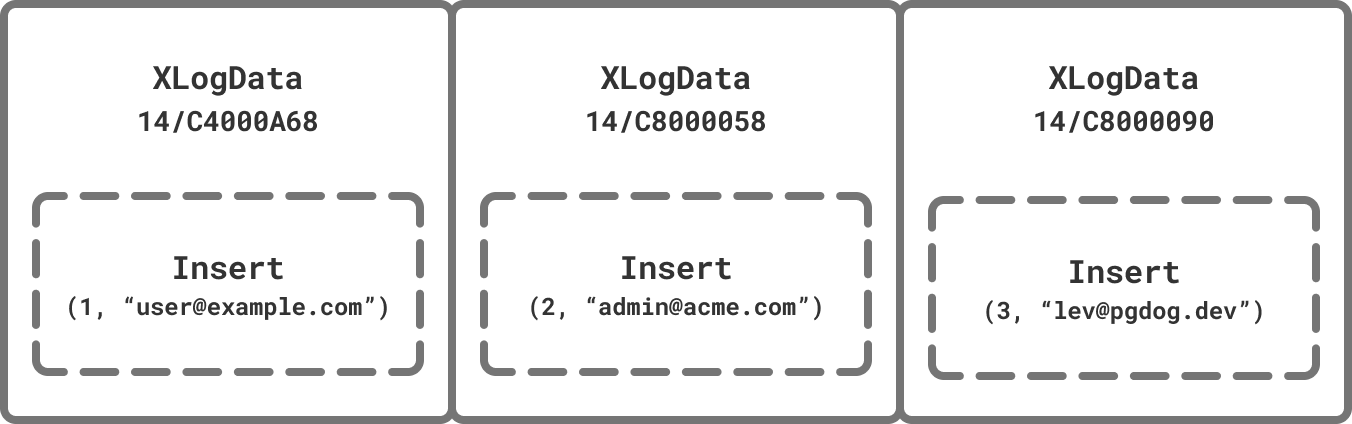 Replication stream has all the data we need to shard it.
Replication stream has all the data we need to shard it.
Since the receiver database created the connection, it knows what to do with these messages. However, in our architecture, PgDog is that receiver. It connects to both the source and destination databases. Postgres connections are created with a specific purpose and can’t process arbitrary messages. Since the shards don’t know they are replicating data, we can’t just forward the WAL messages to them as-is.
To make this work, we rewrite the WAL stream with the standard Postgres query protocol. Since we know the table name, its columns and their data types, we can transform any one of the replication messages into a query. For example an Insert message for the "users" table can be rewritten as:
INSERT INTO users (id, email) VALUES ($1, $2)Running that query has the same effect as applying the Insert itself and allows us to control how we replay the write-ahead log. The replication protocol is tightly coupled to the WAL and needs to be streamed in the exact right order, while the query protocol is flexible: we can send any rows we want, to any database, at any time.
While this works, replication is considerably faster than queries. Queries have to be parsed, planned and executed. Meanwhile, replication is a set of specific instructions to perform a set of changes on tables.
To make it scalable, we took advantage of prepared statements. Instead of sending a query for every message, we prepare it just once per table. Then, for each message Insert/Delete/Update message, we send Bind and Execute messages instead, with the parameters specific to each row.
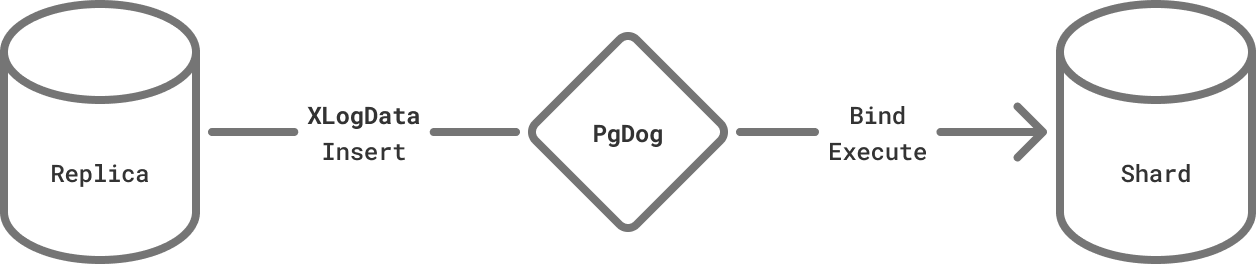 Rewriting the replication stream into the extended protocol.
Rewriting the replication stream into the extended protocol.
This mechanism allows PgDog to push changes to shards. They are just regular Postgres databases, and with share-nothing architecture, multiple instances of PgDog can do the job in parallel. Sharding multi-TB databases is slowly, but surely, becoming routine.
Next steps
The goal for PgDog is to be a push-button scaling solution for Postgres. To achieve this, we are building everything from schema management to distributed transactions.
If you’re looking at scaling Postgres, get in touch. PgDog is an open source project. With an advanced routing layer, connection pooling and now resharding of existing databases, it can scale Postgres to be the heart of your data platform for years to come.
Appendix
RDS databases used in the testing were running on db.m7i.xlarge instances with 4 vCPUs and 16 GB RAM. Each instance was provisioned with 12,000 IOPS and 500MBps EBS throughput, using the gp3 storage tier. The COPY operations were largely I/O bound to EBS. For each additional replica added, overall throughput increased by ~500 MB/second.
PgDog was running on a single c7i.8xlarge instance with 32 vCPUs. It was CPU & network bound only.