Vertical sharding sucks
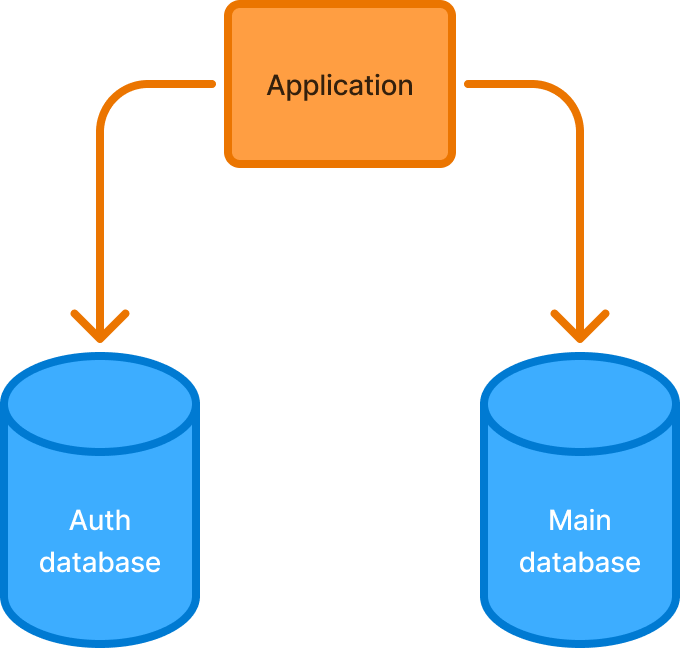
Vertical sharding, sometimes called functional sharding, takes tables out of your main database and puts them somewhere else. Most of the time, it’s another Postgres database. This reduces load on the main DB and gives your app some breathing room to grow.
This also breaks your app into pieces and makes your backend engineers sad. Sad engineers blow up your product roadmap and your hopes of building stuff.
A bit of theory
A bit of a strong start, I agree. If you haven’t had your morning coffee yet, I’d go get one now and come back.
Tables (apps) are never really split up. Even in the perfect world, two apps developed by the same company will need to talk to each other. Sure, that can be done over HTTP, but that doesn’t change the fact that one app is effectively dependent on the other. So while the databases are sharded, the apps are not.
Adding more containers to your Kubernetes cluster adds more 9’s to your SLA. Adding more databases does the opposite. It’s a bit counterintuitive, but here’s why: containers are independent but databases are not. So, if your app needs both DBs to fulfill a request, both DBs have to be working.
Uptime formula
Calculating your uptime is done by taking 100% and subtracting probabilities of failure for each component in your system. If you have a database in RDS, it guarantees that it will work 99.95% of the time. So, if you have one DB, your app’s SLA (in a perfect world) is:
100% - (100% - 99.95%) = 99.95%That was a weird way to remove 0.05 from a 100, but here is why. When calculating uptime of two independent systems, the probability of failure for both is multiplied. So if you have two completely separate databases, and your app can use one or the other (think replicas), your SLA is the probability of both of them failing at the same time:
100% - ((100% - 99.95%) × (100 - 99.95%)) = 99.9975%This is why adding replicas to your database (or containers to your Kube cluster) gives you those two 9’s of uptime.
Now, with vertically sharded databases, both (or more) will be required to fulfill a request. So the probability of either failing means your entire application goes offline. This changes our formula as follows:
100% - ((100% - 99.95%) + (100 - 99.95%)) = 99.90%By adding just one vertical shard, you reduced your uptime by 0.05%. While that seems small, your customers want two 9’s, and that’s enough to put your app out of SLA every year.
Vertical sharding is addictive. Once you start, you won’t stop at one. You’ll keep removing tables, since it has worked for you in the past, and it wasn’t that hard. So you’ll reduce your uptime and increase incidents, and that’s just the beginning of your troubles.
Your code is broken
Well, not entirely. But it’s well on its way to make you hate working with it. I could tell you why, but I’d rather show you. Here is where you started:
user_with_products = User.where(id: user_id).joins(:orders, :products)
This is where you are now:
# Users database
user = User.find(id: user_id)
# Orders database
orders = Order.where(user_id: user_id)
product_ids = []
for order in orders
product_ids << order.product_id
end
# Products database
products = Product.where(id: product_ids)
products_by_order_id = {}
for product in products
if products_by_order_id.include? product.order_id
products_by_order_id[product.order_id] << product
else
products_by_order_id[product.order_id] = [product]
end
end
If you read that carefully, you probably spotted a couple of bugs already. I didn’t, the first time…or the second. But this is what we have to work with, and there is nothing we can do. The models are in different databases, and we can’t let the database do what it does best: join records and search for stuff.
Our app layer is now responsible and we just can’t get that code right. I don’t blame you, set theory is hard, and databases have been optimizing it for decades. Now we have to do it, every time, for every endpoint, forever. Maybe we’ll get better in a few years.
You might be thinking, “well, so what?”. My app is online, it’s kind of working, and my database isn’t on fire anymore. That’s a great feeling. It’s why vertical sharding is done again, and again. It does what it says on the tin.
But what is hurting (or about to) is the product roadmap. Simple things, like fetching things from your database are now hard. They are annoying and, after a while, you just don’t want to do it anymore. So you start taking shortcuts, like duplicating data between databases, just to get your joins back. You don’t really care about database scaling anymore, you just want to get your work done.
You start writing “services” that encapsulate these application-layer joins behind an HTTP (or gRPC) API, and you call them from multiple places in your app. You just added the probability of failure of your databases to your application code, and increased latency two fold.
That’s all you can do. Your feature is months behind schedule and your PM thinks you are on a beach somewhere instead of working. The funny part is you wish you were.
I don’t mean to accuse you of anything. The “you” in this article isn’t you. It’s actually me. I did all of this. As an application engineer and as a database engineer. And the worst part? I did this multiple times. If you ask me today, would I vertically shard again…in all honesty, I wouldn’t be able to tell you for sure.
What went wrong
The Postgres ecosystem doesn’t have an OLTP sharding solution. We are not the “cool” kids like MySQL with Vitess, or DynamoDB, or Cassandra. We’re a bit more practical, love Postgres, and think it can do everything. And that’s actually true. Except the sharding part.
This is what PgDog is set out to do. It may not make us cool, but when our businesses become successful, instead of 2x-ing our error rate, it’ll 10x our productivity.
PgDog is an open source project for sharding Postgres. We are looking for early design partners and contributors. Give us a star on GitHub and get in touch!